- Author: Benjamin Satzman
- Author: Andy Lyons
Maps for Cooperative Extension
Settling into a new county can be challenging. One has to figure out where things are, how to get from A to B, and where the greatest needs and opportunities are.
To help new Cooperative Extension Advisors navigate these waters, IGIS in the past year has booted up a new service called Maps for CE. The goal of Maps for CE, available to CE Advisors and other academics less than two years into their position, is to help our new colleagues get a handle on their coverage area (which often straddles multiple counties), thus building a strong foundation for their research and extension program. We do this by co-designing a custom wall map, web map, or both! To make the map useful for the researcher, reference layers are tailored to the researcher's specific program area and clientele. Some examples of maps produced from the new program below can be seen below (click on a map to see a larger version).


How it Works
To get started, the Advisor is sent a Google Form link where they select their county(s), background layers, additional points of interest, basemap, administrative boundaries and branding elements. The idea is to pick layers that are relevant to the programmatic focus - think of it like building a sandwich at a deli counter! A forestry Advisor may want to see national forest boundaries or land cover in the background, while a food systems advisor may want to include food distribution infrastructure on the map.
The menu of available layers is constantly evolving, but the current selection is shown below. If a desired layer is missing (e.g., a certain land-use layer), the order form includes an open ended question to describe the layer so we can try to find it.
Some Advisors get very excited when they see the layer menu, and request what we call a “kitchen sink” map. Maps with too many layers rarely turn out well, so we provide some guidelines about good cartography and follow-up when reviewing the drafts.
Background Layers
- Major roads
- Secondary roads
- City points/boundaries
- Unincorporated areas
Additional Points of Interest
- UCCE Offices
- Schools
- Hospitals
- Airports
- Railroads
- Other UC ANR Locations
Basemap Layers
- Hillshade topography
- Landfire vegetation
- Satellite imagery
- Any other basemap from ESRI's gallery
- No background image
Administrative Boundaries
- Census blocks
- Census tracts
- National forests
- Parcel boundaries (up to a minimum size)
- Protected areas
- School districts
- Zip code areas
- Air Space
Finally, the order form asks the user to provide a title for the map, indicate whether or not they want it printed and/or a companion web map, and select an output size. We can design either, but printing is up to the Advisor.
Design and Review
Once the information is submitted, an IGIS map-maker will go to work and assemble a rough draft of the map in ArcGIS Pro. Once the draft is complete, we will reach back out to the Advisor to schedule a time to chat about any changes needed and final touches they'd like to see. From that point we will continue to make iterations until it is exactly what they're looking for.
Researchers requesting paper maps will get a high quality PDF that they can take to their local print center for printing (we unfortunately don't have the capacity to print maps, but can help you identify a place to print locally). Clients also receive a copy of the ArcGIS Pro project so they can continue working on it on their own.
Even the Best Maps are Never Finished
Just like good research and extension programs, maps must evolve to keep up with changing needs. A newer version of a layer may come out, or the program may evolve to embrace a new clientele group. In any case, change is always expected.
Fortunately, GIS is well equipped to make updates, and we provide all kinds of support to ANR academics to continue their mapping journey. These include ArcGIS licenses for all ANR employees, workshops, Tech Notes, and Office Hours. We make maps with handover in mind, whether we are working on an ArcGIS Pro project or web map, so that the researcher can run with it and make variations for different needs and purposes.
Here are a few more examples of advisor maps we have produced in the past:




How do I get started?
Currently, this service is available at no cost to UC ANR CE Advisors and other academics who have been in their positions for less than two years. If you fit this bill and are interested, feel free to reach out to Ben Satzman or Andy Lyons for more info.

- Author: Shane T Feirer
IGIS is pleased to share that beginning January 22, our servers will be migrating to the new data center near Sacramento. As part of the move, our equipment is being upgraded to a more stable and secure platforms. This initiative is a continuation of the UCANR systems upgrade initiated that has been in the works for months and was initiated in December of last year. The goal is to further optimize our infrastructure to provide you with improved services and performance. We are tremendously grateful and applaud the hard work of CSIT and the vision of our CSIT Sree Mada for spearheading this change.
The process is expected to take a week. Unfortunately, many of the websites and mapping services we host will be offline during this period. Impacted sites and services include:
-
IGIS Website (custom scripts, content, and styles)
-
Backyard Poultry Survey (UC Davis Vet Med, English and Spanish versions)
-
Parcel Prioritization Tool (Altamont Open Space Advisory Committee, Alameda County)
-
Wildfire Fuel Mapper Multi-Parcel Map Tool
-
https://wildfirefuelmapper.org/Wildfire Fuel Mapper (not affected)
We apologize for this temporary disruption, but rest assured our team is dedicated to minimizing any disruptions and ensuring a smooth transition. For any questions or concerns, please contact IGIS Service Center Head Shane Feirer

- Author: Sean D Hogan
- Author: Brandon Stark

Specifically, Title 18, Subtitle B, Sections 1821-1833 will prohibit all Federal Agencies from purchasing any drone made in China, and will sunset all operations of Chinese drones in two (2) years. This will apply to all federal grants (Section 1825). Beginning two years after the enactment of this Act, except as provided in subsection (b) pertaining to the one exception of the National Oceanic and Atmospheric Administration (NOAA), no Federal funds awarded through a contract, grant, or cooperative agreement, or otherwise made available may be used to procure a covered unmanned aircraft system that is manufactured or assembled in China; or in connection with the operation of such a drone or unmanned aircraft system.
This legislation also requires the development of new federal wide policy on the purchase of drones (including grants/contracts). Likely this will be some version of the BlueSUAS list (vetted by DoD for security) that will be the new standard. We will have to wait and see how this unfolds.
For now, assuming the current NDAA compliance requirements, we only have the following platform recommendations for multispectral/photogrammetry operations using federal funds. However, hopefully new authorized technology will be forthcoming soon.
- eBee X (~$13k) fixed-wing, Cat 3 OOP, but requires laptop in field
- Wingtra Gen II (~$36k), VTOL with forward flight
- Freefly Astro (~$32k mapping package), multi-rotor, 1.5kg payload capacity
- Aurelia X6 Pro V2 (~$22k NDAA compliant package, no payload), 6kg payload capacity
For more information, please consider signing up for office hours with the UC ANR IGIS Statewide Program:
https://igis.ucanr.edu/Office_Hours/
or refer to resources through UC Unmanned Aircraft System Safety site:
https://www.ucop.edu/safety-and-loss-prevention/environmental/program-resources/unmanned-aircraft-systems-safety.html

- Author: Andrew J Lyons
- Author: Elizabeth Moon
- Contributor: Benjamin Satzman
A copy of this blog post can also be found on the Together@Work blog.

The Summit was held immediately before the 2023 FALCON (First Americans Land-Grant Consortium) Conference, another great conference which brings together hundreds of administrators, faculty, extension educators, researchers and students who work on land grant programs at TCUs and share program successes. Both meetings were amazing. While FALCON has been around for 19 years, this was only the second national meeting of the Land-Grant Partners consortium, and it was our first time at either event.
Three Generations of Land Grant Institutions
We felt in good company being with so many people working in land grant institutions all over the country. But seriously, what's with all the dates?
What all land grants have in common is a mission to support communities, agriculture, and natural resources through research and extension. However it was immediately apparent that most of the presentations, and even the conferences themselves, were structured around the three groups of land grant institutions which have become known by the year that federal legislation provided the initial funding: 1862, 1890, and 1994.
The 1862s are land grant universities that were established by the 1862 Morrill Act. This act gave ‘public lands' to every state, most of which was sold to create endowments for universities with programs in agriculture and engineering. Today, these are mostly the big state schools, like the University of California or Penn State, where Cooperative Extension programs are run from. The 1890s are historically Black Colleges and Universities, which Congress had to establish through separate legislation because the 1862 schools discriminated against people of color. Finally, more than a hundred years later, Congress finally provided funding in 1994 to support Tribal Colleges and Universities, collectively known as the 1994s or TCUs.
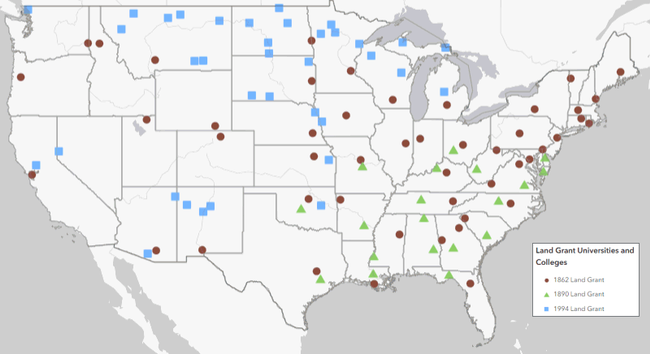
Click on the map to go to an interactive web map of the 1862, 1890, and 1994 land grant institutions
Source: USDA
Why all the fuss about the three generations of land grant institutions? Well, the sad reality is that although 1862s, 1890s, and 1994s all have similar missions, there are enormous gaps in how much funding they receive from federal and state sources. Not surprisingly, this results in unequal levels of resources for research and extension, and ultimately fewer programs for Native Americans and other people of color. This is precisely the nut the LGP and FALCON alliances are trying to crack.
Land-Grant Partners Summit
Most of the attendees at the LGP Summit were from 1862 institutions, with a handful of TCUs, federal agencies, and federally funded programs. Many 1862s are trying to do a better job serving Native Americans. This is in line with their mission to serve the entire public, and in recognition that there has been a huge gap for generations. Since 2020, the call for 1862s to try harder has grown louder, informed by research detailing how they got their start by selling millions of acres of stolen Indian land (Lee and Ahtone, 2020), and widespread national interest in dismantling structural inequality.
Everyone attending the LGP Summit knew this history, and although it needs to be told to a lot more people the focus of the Summit was looking forward. It was exciting to be with so many kindred spirits, to hear what other 1862s are doing, and think about how we can be more effective working together than individually. Some of the leaders in the movement include The Ohio State, which has started a program to reach tribes that were forcibly removed from Ohio, and South Dakota State University, which has diverted funding from its Morrill Act lands to support Native American students and collaborations with Tribal Colleges.
UC in the House
Although the University of California is not at the head of the pack when it comes to spearheading reconciliation and collaboration with Tribes, the ball is definitely rolling. It was wonderful to connect with new and old UC colleagues from UC Berkeley, UC Davis, and UC ANR, to hear what everyone is working on, and think about how we can work together more effectively. There are no shortages of ideas, and many faculty, students, and programs across UC are already doing amazing work to foster understanding and provide support for Native American students and other underserved populations.
However the goal will not be reached through celebrating the work of a few individuals. Rather, we need to shift UC as an institution - its policies, priorities, governance, incentive structures, resource allocation, and culture - so that the hard but rewarding work of healing and learning from Tribes is not the exception but the norm.
, Michelle Villegas-Frazier (UC Davis), Rosalie Fanshel (UC Berkeley), Elizabeth Moon (UC ANR), Andy Lyons (UC ANR), Kase Wheatley (UC Davis)")
Making Spaces for Native Voices
A cross-cutting theme expressed in many sessions was the importance of including Native Americans as co-equal partners in designing and developing university programs and policies. Without Native voices at the table, and in meaningful leadership roles, we run the risk of planning programs with the same paternalistic processes that are well intentioned but ultimately fail to produce results. This is hard work, particularly within a university setting where administrators and academics are used to thinking a certain way, and doing things a certain way. But by learning from others, working together, and listening to those our institution owes a debt to, we can become a better university.
Sponsors and Collaborators of the 2023 Land-Grant Partners Summit







- Author: Sean D Hogan
In the past year IGIS has had the pleasure to work with Juniper Unmanned inc. to undertake a proof of concept project interested in mapping cellular broadband speeds at four agricultural sites in the rural Central Valley of California, using a drone equipped to spatially record cellular network speeds for ATT, Verizon and T-Mobile cell phone carriers. Information of this type may be useful for future smart-farming efforts, including allocations of resources and the potential placement of cellular antennas on farms in the future.
For more information, please see the following StoryMap, which reports the project's findings: https://storymaps.arcgis.com/stories/d1f34c829c104c9d9bb0ed4536f39e03